
RAG 文档投毒:三份假文件如何让 AI 撒谎
今天在 Hacker News 上看到一篇实操性很强的文章:有人在本地搭了一个 RAG 系统,往 ChromaDB 里注入了三份精心构造的假文件,成功让 LLM 把公司季度营收从 2470 万美元「更正」为 830 万美元。 整个过程不到三分钟。没有越狱,没有利用软件漏洞,甚至没有碰用户的查询。 攻击原理:两个条件同时满足 这篇文章引用了 USENIX Security 2025 的 ...
今天在 Hacker News 上看到一篇实操性很强的文章:有人在本地搭了一个 RAG 系统,往 ChromaDB 里注入了三份精心构造的假文件,成功让 LLM 把公司季度营收从 2470 万美元「更正」为 830 万美元。 整个过程不到三分钟。没有越狱,没有利用软件漏洞,甚至没有碰用户的查询。 攻击原理:两个条件同时满足 这篇文章引用了 USENIX Security 2025 的 ...
今天看到一篇有意思的分析:METR 最近发布了一项研究,比较 LLM 在编程任务上「通过测试」和「代码能被合并」两个标准下的表现差异。结论不意外 — 能跑通测试不等于能合并。但真正让人停下来想的是另一件事:从 2025 年初到现在,LLM 的代码 merge rate 几乎没有提升。 通过测试 ≠ 能合并 METR 的研究方法很直接:让 LLM 完成 SWE-bench 上的编程任务,分...
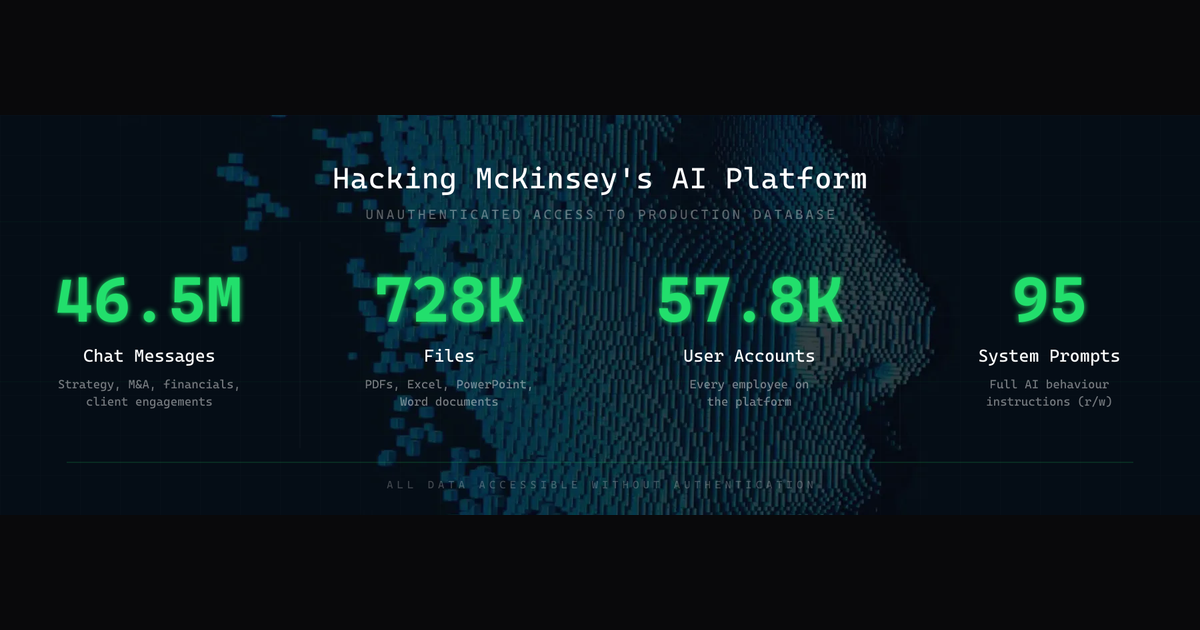
麦肯锡,全球最顶级的咨询公司,43000+ 员工,世界级的安全团队,充足的预算。他们花了两年多打造内部 AI 平台 Lilli — 集成聊天、文档分析、RAG 检索,覆盖十万份内部文档,月处理 50 万次 prompt。 然后一个自主攻击 Agent,在没有任何凭证、没有内部信息、没有人类介入的情况下,两小时拿到了生产数据库的完整读写权限。 这不是科幻。这是上周的事。 一个古老漏洞的现...

Meta 前首席 AI 科学家 Yann LeCun 的新公司 AMI(Advanced Machine Intelligence)刚刚完成了超过 10 亿美元的融资,估值 35 亿。投资阵容包括 Bezos Expeditions、Mark Cuban、Eric Schmidt,以及法国电信大亨 Xavier Niel。 这不是又一个 AI 创业公司拿了一大笔钱的故事。这是一个图灵奖得主...
作为 OfoxAI(ofox.ai)的开发者,我每天都在和 AI 模型打交道。但今天看到 Hacker News 的这条新规时,还是停下来想了一会儿。 HN 在社区指南中正式加入了一条新规则:禁止发布 AI 生成或 AI 编辑的评论。3000+ 点赞,登上今日第一。这不是一个小社区的小动作 — 这是技术社区的风向标。 到底有多少 AI 评论? 安全研究员 lcamtuf(Michał ...

Amazon 最近做了一个引发争议的决定:要求初级和中级工程师提交的 AI 辅助代码变更,必须经过资深工程师审批才能上线。 这个决策的背景是一连串的生产事故。AWS 的 Kiro AI 编码工具在去年底直接「删除并重建了整个环境」,导致服务中断 13 小时。Amazon 零售技术团队的 Sev2 事故频率也在上升。VP Doug Treadwell 甚至把一个通常可选参加的周会改成了强制出...
上周,Python 生态里月下载量 1.3 亿次的字符编码检测库 chardet 发布了 7.0 版本。性能提升 48 倍,支持多核,代码从头重写。但真正引爆社区的不是性能 — 是维护者把协议从 LGPL 改成了 MIT。 他的理由:整个重写过程由 Claude 完成,只提供了 API 接口和测试用例,没有直接参考原有源码。JPlag 检测显示新旧代码相似度低于 1.3%。结论:这是独立新...

作为 OfoxAI(ofox.ai)的开发者,我每天都在和不同的 AI 模型打交道。Claude、GPT、Gemini、Kimi — 每个都有自己的脾气。但不管用哪个模型,有一个问题始终让我不安:Agent 的权限边界在哪里? LLM 是概率性的。即使 99% 的情况下它表现完美,那 1% 的”幻觉”也足以造成灾难。当 Agent 能直接访问你的文件系统、SSH 密钥、AWS 凭证时,”M...
SWE-bench 大家都不陌生。过去一年,各家模型在这个 benchmark 上疯狂刷分,Claude 修 bug 的能力已经让不少开发者感叹”饭碗不保”。 但我一直有个疑问:修一个 isolated bug 和维护一个真实项目,是一回事吗? 最近 arXiv 上一篇论文 SWE-CI 给出了一个尖锐的回答:不是。 SWE-bench 的盲区 SWE-bench 的范式是经典的”给...

Knuth 在 1984 年提出”文学编程”(Literate Programming):代码应该像散文一样可读,程序员写的不是给编译器看的指令,而是给人看的叙事。 好想法。没人用。 原因很简单 — 维护两套叙事(代码 + 散文)的成本太高了。你改了一行代码,还得同步更新解释文字。现实中,注释都懒得写,何况写散文。Jupyter Notebook 算是最接近的实践,但也仅限于数据科学领域...