Agent 真正的瓶颈,不是模型,而是工具层
这几天看完 HN 上那篇“从零搭一个 AI Agent”的讨论,我的结论很直接:今天做 Agent,模型当然重要,但真正决定它能不能落地的,往往不是模型本身,而是工具层。 很多人一上来就问“该选 Claude 还是 GPT,还是 Gemini”。这个问题不算错,但它通常问早了。因为 Agent 不是一个会聊天的模型,而是一套会执行的系统。模型负责推理,工具负责行动,编排层负责把两者拴在一起...
这几天看完 HN 上那篇“从零搭一个 AI Agent”的讨论,我的结论很直接:今天做 Agent,模型当然重要,但真正决定它能不能落地的,往往不是模型本身,而是工具层。 很多人一上来就问“该选 Claude 还是 GPT,还是 Gemini”。这个问题不算错,但它通常问早了。因为 Agent 不是一个会聊天的模型,而是一套会执行的系统。模型负责推理,工具负责行动,编排层负责把两者拴在一起...

Meta AI 官方博客首页截图。重点不在“又发了什么大模型”,而在工程化能力如何被抬到台前。 这两天看官方博客和行业讨论,我越来越确定一件事:AI 领域的主战场正在变。 前几年大家比的是参数、榜单、演示效果,谁在单轮问答里更像“人”,谁就更容易赢得注意力。现在不是了。真正拉开差距的,开始是三件事:能不能稳定接工具,能不能在长链路任务里不翻车,能不能把测试、监控、回滚和权限控制做成一套工...

The Speed of Prototyping in the Age of AI 原文配图 今天看到 HN 上一篇《The Speed of Prototyping in the Age of AI》,标题不新鲜,但问题很硬:AI 让“做出来”这件事几乎没有门槛之后,真正稀缺的东西到底是什么? 我自己的答案是:不是代码量,也不是想法数量,而是判断力。以前一个产品原型从零到一,最大成本通...
最近在 Hacker News 上看到一个叫 Open Envelope 的项目,标题很直白:它想为 AI agent teams 定义一个开放 schema。这个方向我反而觉得比“又一个能跑 demo 的 agent 框架”更值得看。前者在争一个接口层,后者通常只是在重复调度、记忆、工具调用这几件事。 Agent 这两年最容易被高估的地方,就是大家把注意力都放在“单个 agent 会不会...
作为 OfoxAI(ofox.ai)的开发者,我对这类发布有个固定判断:别只看“模型有多强”,要看它开始接管多少工作流。Google I/O 2026 的这篇官方稿,真正值得注意的不是又一次“更聪明了”,而是 Gemini 被摆到了一个更像操作系统的位置上。 Google I/O 2026 的主视觉,重点已经不是单点能力,而是整个产品矩阵的协同。 这篇文章里最重要的信号有三个。 第一...
Anthropic 收购 Stainless,把注意力从“模型有多强”拉回到“模型怎么稳定接入真实业务”。 Anthropic 收购 Stainless 这件事,我第一反应不是“又一家 AI 公司并购”,而是一个信号:AI 竞争的重心,正在从模型参数和 demo 效果,转向连接层、工具层和工程稳定性。 Stainless 做的是 API 生成与 SDK 体验这一层。这个层看起来不性感,但...

Meta AI 这次的新表述很直接:不是再讲一个单点模型能力,而是把“个人超级智能”作为产品叙事往前推。标题听起来像愿景,实际上更像一次路线宣言。它告诉外界,Meta 不想只做一个模型供应商,而是想把模型能力、分发渠道和用户关系一起握在手里。 Meta AI 这次把叙事重点放在“个人超级智能”上,核心不是单个 benchmark,而是整个产品方向。 这次更新真正重要的,不是“更强”,而...

Google 在 I/O 2026 相关更新里,继续把搜索从“信息检索”往“任务入口”推进。 Google 这次的搜索更新,核心不是“又加了一个 AI 按钮”,而是把搜索结果页重新定义成了一个可以继续执行任务的界面。过去我们把搜索当成查资料的地方,现在它更像是一个临时工作台:先理解问题,再给答案,再给下一步动作。 这类变化看起来温和,实际很重。因为搜索是互联网里最稳定的入口之一。一旦入口...

Cloudflare 这篇关于 AI code review 的文章,表面上讲的是“怎么让模型帮忙审 PR”,本质上讲的是另一件事:当 AI 进入代码评审流程后,系统到底如何保持可靠性。 很多人一上来就问模型准不准、召回率高不高、能不能替代 reviewer。这个问题问浅了。真实场景里,code review 从来不是单纯的分类任务,它更像一个带约束的决策系统:要看变更上下文、历史讨论、风...
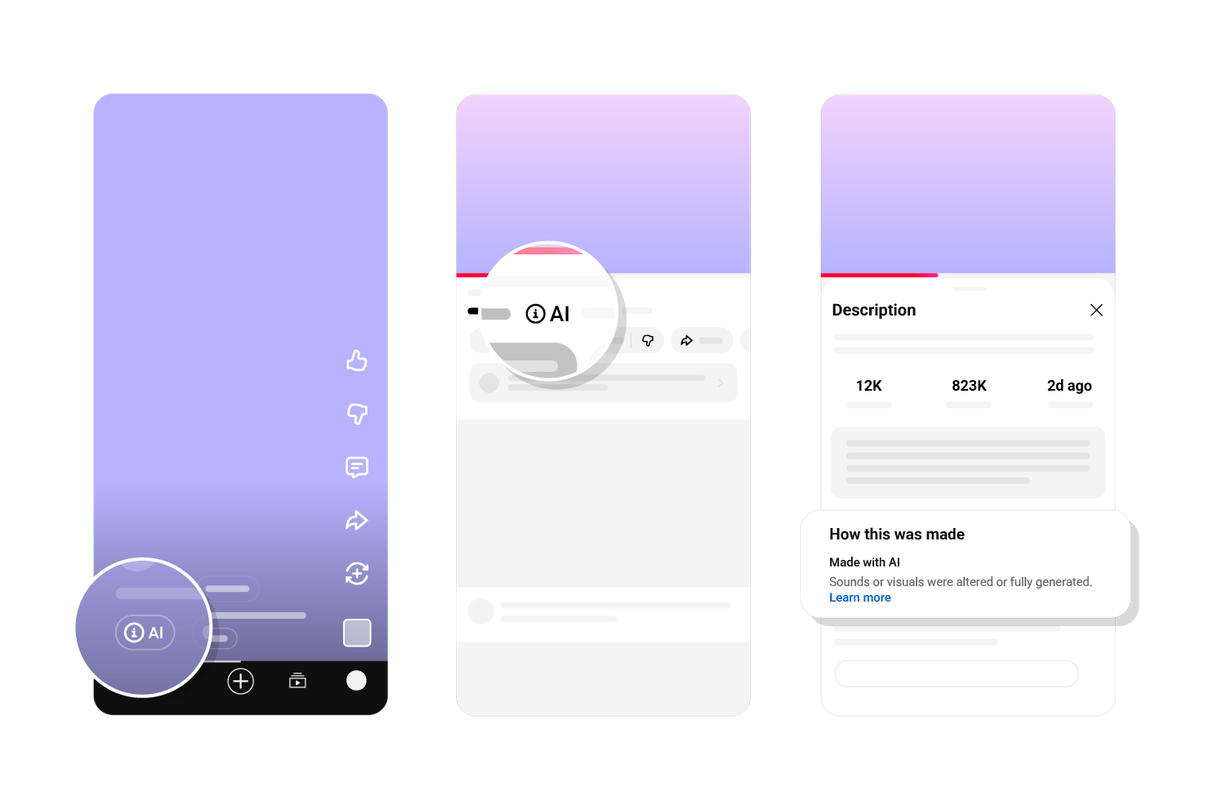
YouTube 这次更新的重点,不是“AI 视频更好看了”,而是“平台开始正式管理 AI 内容的可见性”。 它做了两件事:一是让创作者更明确地声明视频里是否包含生成式 AI;二是把这类信息更直观地展示给观众。表面上看,这是一个标签系统。实际上,它是在把“内容可信度”从创作者的自述,变成平台层面的产品能力。 YouTube 开始把 AI 内容标识做成更显眼的产品能力,透明度变成了分发的一...