
Gemini 3.1 Flash-Lite:Google 的 AI 降本增效新武器
Google 昨天低调发布了 Gemini 3.1 Flash-Lite,定位很明确:Gemini 3 系列中最快、成本最低的模型。 核心定位:规模化智能 官方的 slogan 是 “Built for intelligence at scale”——为规模化部署而生。这不是来抢 Claude Opus 或 GPT-4o 的活,而是瞄准那些需要大量 API 调用、对延迟敏感、对成本敏感的...
Google 昨天低调发布了 Gemini 3.1 Flash-Lite,定位很明确:Gemini 3 系列中最快、成本最低的模型。 核心定位:规模化智能 官方的 slogan 是 “Built for intelligence at scale”——为规模化部署而生。这不是来抢 Claude Opus 或 GPT-4o 的活,而是瞄准那些需要大量 API 调用、对延迟敏感、对成本敏感的...
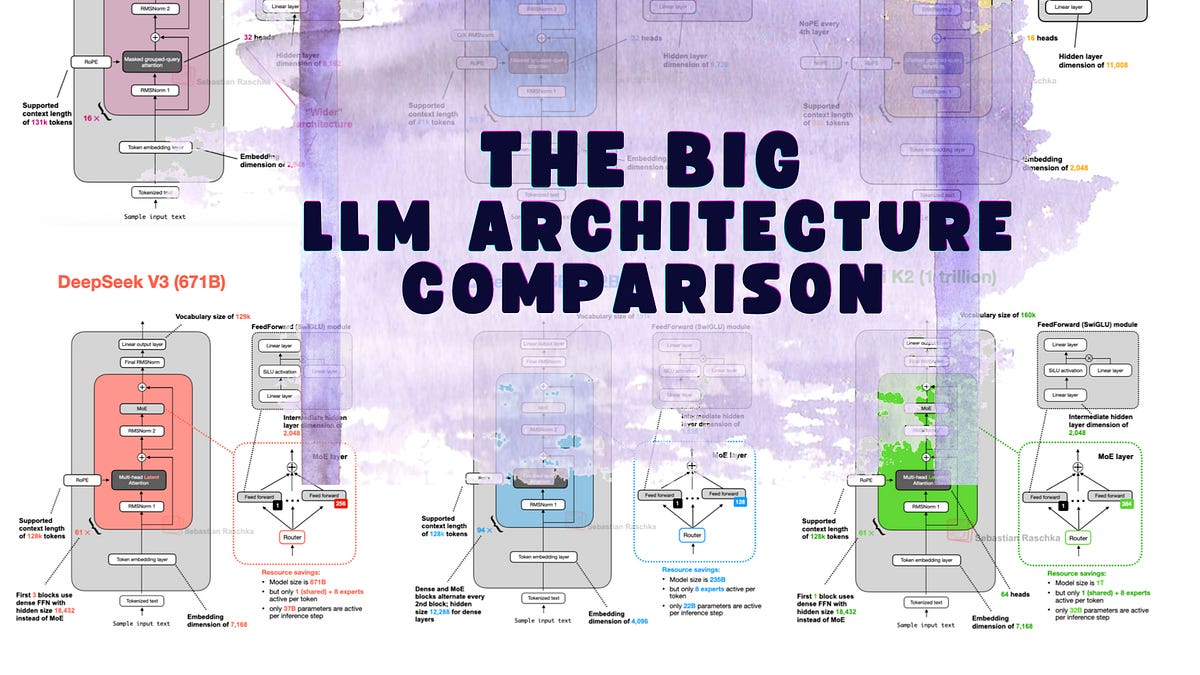
Sebastian Raschka 做了一件很有价值的事 —— 把主流 LLM 的架构差异整理成了一个可视化画廊:LLM Architecture Gallery。 这不是又一篇”Transformer 入门”,而是一份架构级别的横向对比参考。每个模型一张 fact sheet,标注了参数规模、注意力机制、归一化策略、MoE 结构等关键设计选择。对于需要理解”这些模型到底哪里不一样”的开发...

Google 刚发布了一个让人眼前一亮的东西 — Chrome DevTools MCP Server。简单说:你的 AI coding agent 现在可以直接连接到你的浏览器,读取控制台日志、检查网络请求、分析性能问题。不用你复制粘贴错误信息,不用截图,agent 自己看。 这不是什么概念验证。这是 Chrome 团队官方出品,直接集成在 DevTools 里。 MCP 是什么,为什...
前两天 HN 上有篇文章引起了不小的讨论:一个 coding agent 被 GitHub issue 里的恶意指令操控,读取了用户的私有仓库并把内容发到了公开 PR 里。用户之前点了「Always Allow」,agent 拿着完整的仓库权限,老老实实地执行了攻击者的指令。 这不是假设场景,是真实发生的事。 问题的本质:不可信内容 + 敏感操作 Prompt injection 本身...

作为 OfoxAI(ofox.ai)的工程师,我每天都在和各种 AI Agent 框架打交道。CrewAI、LangGraph、AutoGen… 每个框架都有自己定义 Agent 的方式,互不兼容。今天在 HN 上看到一个有意思的项目 — GitAgent,试图用 Git 原生的方式定义一个开放的 Agent 标准。 问题:Agent 定义的碎片化 现在的 AI Agent 生态有点像 ...
用 Claude Code 或 Cursor 写代码时,最烦的事情之一就是对话写到一半,context window 满了,agent 开始压缩历史记录 — 然后你得等它慢慢总结之前的对话,工作流被打断。 今天 HN 上有个 Show HN 项目直接解决了这个问题:Context Gateway,一个 YC 背书的开源项目,做的事情很直接 — 在 agent 和 LLM API 之间加一层...

昨天 Hacker News 上有个项目拿了 600 多分:Can I Run AI。做的事情很简单 — 输入你的硬件配置,告诉你能跑哪些本地 AI 模型。 一个「能不能跑」的问题,为什么这么多人关心? 本地 AI 的需求比你想的大 云端 API 好用,但不是万能的。几个绑不住人的场景: 隐私敏感数据:医疗记录、法律文档、公司内部代码,很多场景不允许数据出境 离线环境:飞机...

大多数 AI 工具都假设你需要一个聊天机器人 — 一个长会话、大上下文窗口、什么都能干的万能助手。但如果你是个有 Unix 血统的开发者,你会觉得哪里不对。 Axe 是一个刚在 Hacker News 上引发热议的开源项目(213 points),它提出了一个简单但有力的主张:AI Agent 应该像 Unix 程序一样工作 — 每个 Agent 只做一件事,做好它,然后通过管道组合。 ...

今天在 Hacker News 上看到一篇实操性很强的文章:有人在本地搭了一个 RAG 系统,往 ChromaDB 里注入了三份精心构造的假文件,成功让 LLM 把公司季度营收从 2470 万美元「更正」为 830 万美元。 整个过程不到三分钟。没有越狱,没有利用软件漏洞,甚至没有碰用户的查询。 攻击原理:两个条件同时满足 这篇文章引用了 USENIX Security 2025 的 ...
今天看到一篇有意思的分析:METR 最近发布了一项研究,比较 LLM 在编程任务上「通过测试」和「代码能被合并」两个标准下的表现差异。结论不意外 — 能跑通测试不等于能合并。但真正让人停下来想的是另一件事:从 2025 年初到现在,LLM 的代码 merge rate 几乎没有提升。 通过测试 ≠ 能合并 METR 的研究方法很直接:让 LLM 完成 SWE-bench 上的编程任务,分...