Research-Driven Agents:让 AI 先读论文再写代码
最近 SkyPilot 团队发了一篇博客,标题很直白:Research-Driven Agents — When an agent reads before it codes。在 Hacker News 上拿了 142 分,评论区也吵得不错。
核心观点一句话概括:AI coding agent 的瓶颈不是写代码的能力,而是”知道该写什么”的能力。
问题出在哪
现在的 coding agent(Cursor、Copilot、Codex 等)已经很能写了。给个 prompt,几秒钟生成几百行代码,语法正确,类型安全,测试都能过。但有个致命问题:它们不做调研。
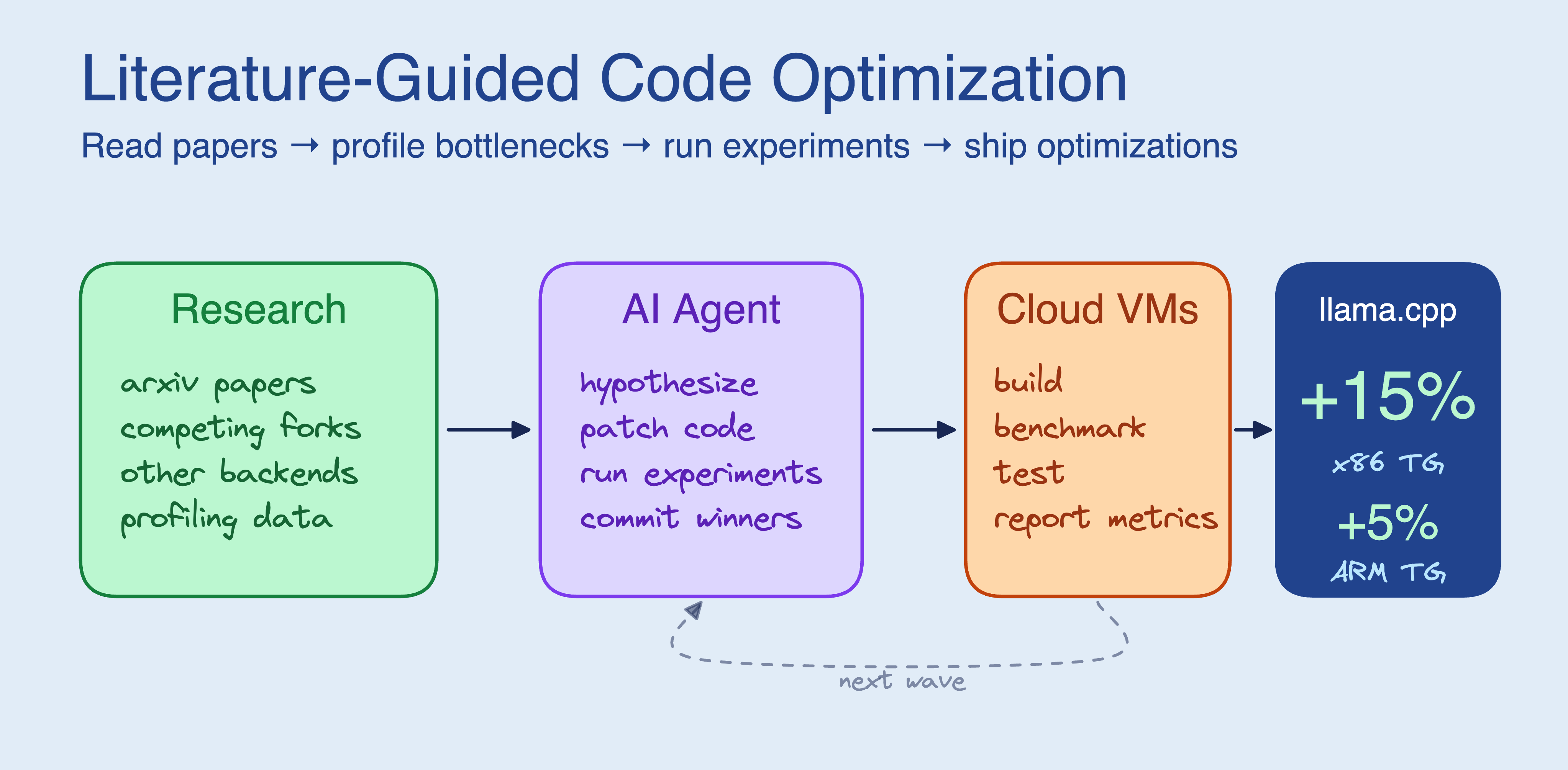
SkyPilot 的 Research-Driven Agent 工作流
想象一个场景:你让 agent 实现一个分布式锁。它会直接开始写 Redis SETNX —— 这是最常见的方案,训练数据里一堆。但如果你的场景是跨区域的、需要容错的,Redlock 可能才是正确答案。更进一步,如果你看过 Martin Kleppmann 对 Redlock 的批评论文,你可能会选择完全不同的方案。
人类工程师在动手之前会先查文档、读论文、看 issue。Agent 不会。 这就是 research-driven 要解决的问题。
Research-Driven 的思路
SkyPilot 的方案分三步:
- 问题理解(Understanding):Agent 先分析任务,拆解出”我需要了解什么才能动手”
- 主动调研(Research):搜索文档、论文、GitHub issue、Stack Overflow,建立上下文
- 知情编码(Informed Coding):带着调研结果写代码,而不是凭训练数据的”印象”
听起来简单?但细节里全是魔鬼。
调研多深算够?搜到矛盾的信息怎么办?什么时候该停止调研开始动手?这些都是工程问题,不是简单加个 RAG 就能解的。
为什么这个方向重要
从我的实际体验来看,coding agent 犯的错 80% 不是”写不对”,而是”写错了东西”。方向错了,代码写得再漂亮也白搭。
这背后有个更大的趋势:Agent 正在从”执行工具”进化为”决策主体”。
第一代 agent:你告诉它做什么,它做。(自动补全、代码生成) 第二代 agent:你告诉它目标,它决定怎么做。(Cursor、Devin) 第三代 agent:你告诉它目标,它先调研、再规划、再执行。(Research-Driven)
每一代的核心区别不是”写代码的能力”变强了,而是”做决策的范围”变大了。
冷水时间
也得说说局限。
调研质量依赖搜索质量。 如果 agent 搜到的第一个结果就是过时的 Stack Overflow 回答,它可能被带偏。garbage in, garbage out。
调研增加延迟。 现在的 coding agent 快就是优势。让它先花 30 秒读论文再写,用户能接受吗?这是产品层面的取舍。
调研不等于理解。 人类读论文能举一反三,agent 读论文只能提取信息。从”知道”到”理解”,中间还差一个 reasoning 的飞跃。
工程师该怎么想这事
不管你用不用 SkyPilot 的方案,这个思路值得吸收:在让 AI 动手之前,先确保它知道足够多。
具体到实践:
- 给 agent 更丰富的上下文(项目文档、架构决策记录、技术选型理由)
- 把调研作为 agent workflow 的显式步骤,而不是隐式依赖
- 对 agent 的输出做 review 时,重点看”它做了什么假设”,而不只是”代码对不对”
Agent 越来越能干了,但方向感比执行力更稀缺。
如果你需要在不同 AI 模型之间快速切换和对比(比如让 Claude 做调研、GPT 做生成、Gemini 做验证),推荐试试 OfoxAI(ofox.ai)— 一个账号搞定所有主流模型。