LLM Architecture Gallery:一张图看懂主流大模型架构差异
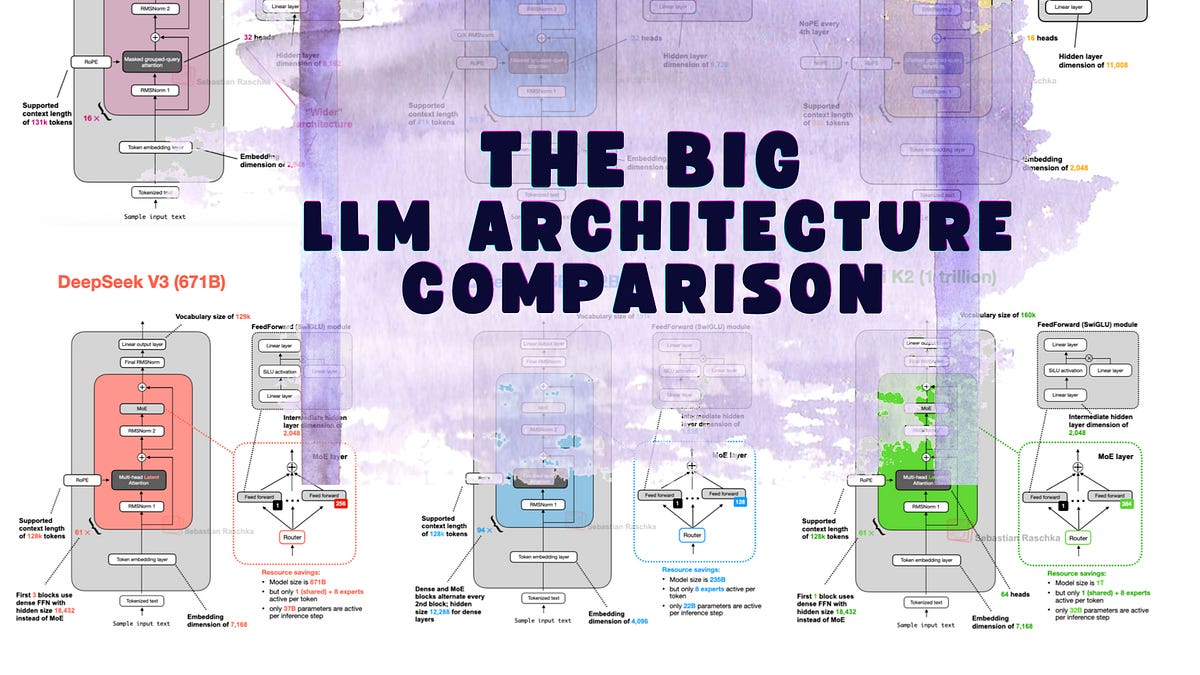
Sebastian Raschka 做了一件很有价值的事 —— 把主流 LLM 的架构差异整理成了一个可视化画廊:LLM Architecture Gallery。
这不是又一篇”Transformer 入门”,而是一份架构级别的横向对比参考。每个模型一张 fact sheet,标注了参数规模、注意力机制、归一化策略、MoE 结构等关键设计选择。对于需要理解”这些模型到底哪里不一样”的开发者来说,这可能是目前最直观的参考资料。
为什么架构细节仍然重要
很多人觉得大模型时代只需要调 API,架构是研究者的事。这个观点在 2024 年可能成立,但到了 2026 年,情况变了:
- 本地部署越来越普遍。选 Llama 还是 OLMo,GQA 还是 MHA,直接影响你的推理延迟和显存占用
- MoE 架构成为主流。DeepSeek V3 的 671B 参数中只激活 37B,但你需要理解 shared expert 和 routing 机制才能做好量化和部署优化
- 微调需要架构认知。不同的归一化策略(pre-norm vs post-norm)对 LoRA 适配的效果影响显著
几个值得关注的架构趋势
从 Gallery 中可以看到几个清晰的趋势:
1. GQA 已经赢了
Grouped Query Attention 几乎成为标配。从 Llama 3 到 Gemma 2,主流 dense 模型都在用 GQA 替代传统 MHA。原因很简单 —— KV cache 的显存压力在长上下文场景下是硬约束,GQA 在质量和效率之间找到了最佳平衡点。
2. MLA 是 DeepSeek 的独门武器
Multi-head Latent Attention 是 DeepSeek V3/R1 的核心创新之一。通过将 KV 投影到低秩潜空间,MLA 在保持模型质量的同时大幅降低了推理时的 KV cache 开销。目前还没有其他主流模型跟进这个设计,但我觉得这只是时间问题。
3. 归一化策略在分化
OLMo 2 选择了”inside-residual post-norm”而不是常见的 pre-norm,声称这对训练稳定性有帮助。这类看似微小的设计选择,往往是几千 GPU-hours 的实验结果。Gallery 把这些细节标注出来,省去了你翻论文的时间。
实用价值
对我来说,这个 Gallery 最大的价值是快速定位差异。比如你在评估两个 7B 模型做本地部署,打开对应的 fact sheet 一比较,注意力机制、FFN 结构、上下文长度一目了然。比读两篇论文的 Section 3 快多了。
Raschka 甚至把这个做成了实体海报(14570 × 12490 像素的 PNG),挂在工位上当参考也不错。
写在最后
大模型不是黑盒。即使你只是 API 用户,理解架构差异也能帮你做出更好的模型选择 —— 什么场景用 dense,什么场景用 MoE,什么时候长上下文真的有用。
如果你需要在 Claude、GPT、Gemini 等不同架构的模型之间灵活切换,试试 OfoxAI(ofox.ai)—— 一个账号聚合主流 AI 模型,自己体验不同架构在实际任务上的差异。