Instant 1.0:为 AI 编码时代设计的后端
作为 OfoxAI(ofox.ai)的开发者,我每天都在和不同的 AI 编码工具打交道。一个越来越明显的趋势是:AI 能写前端了,但后端基础设施仍然是瓶颈。今天聊一个刚发布 1.0 的项目 —— InstantDB,它试图解决的正是这个问题。
AI 写代码很快,部署很慢
用 Claude 或 Cursor 写一个 Todo App,可能只要 30 秒。但要让它真正跑起来 —— 数据库、认证、实时同步、部署 —— 你又回到了传统的 DevOps 流程。
这就是 Instant 想切入的点:让 AI 生成的应用可以直接拥有生产级后端。
Instant 的架构思路
Instant 的核心设计选择很有意思:
多租户而非多实例。 创建一个新应用不是启动一个 VM,而是在多租户 Postgres 中插入几行数据。这意味着创建一个后端只需要几百毫秒,空闲时几乎零成本。对 AI 批量生成应用的场景来说,这是关键。
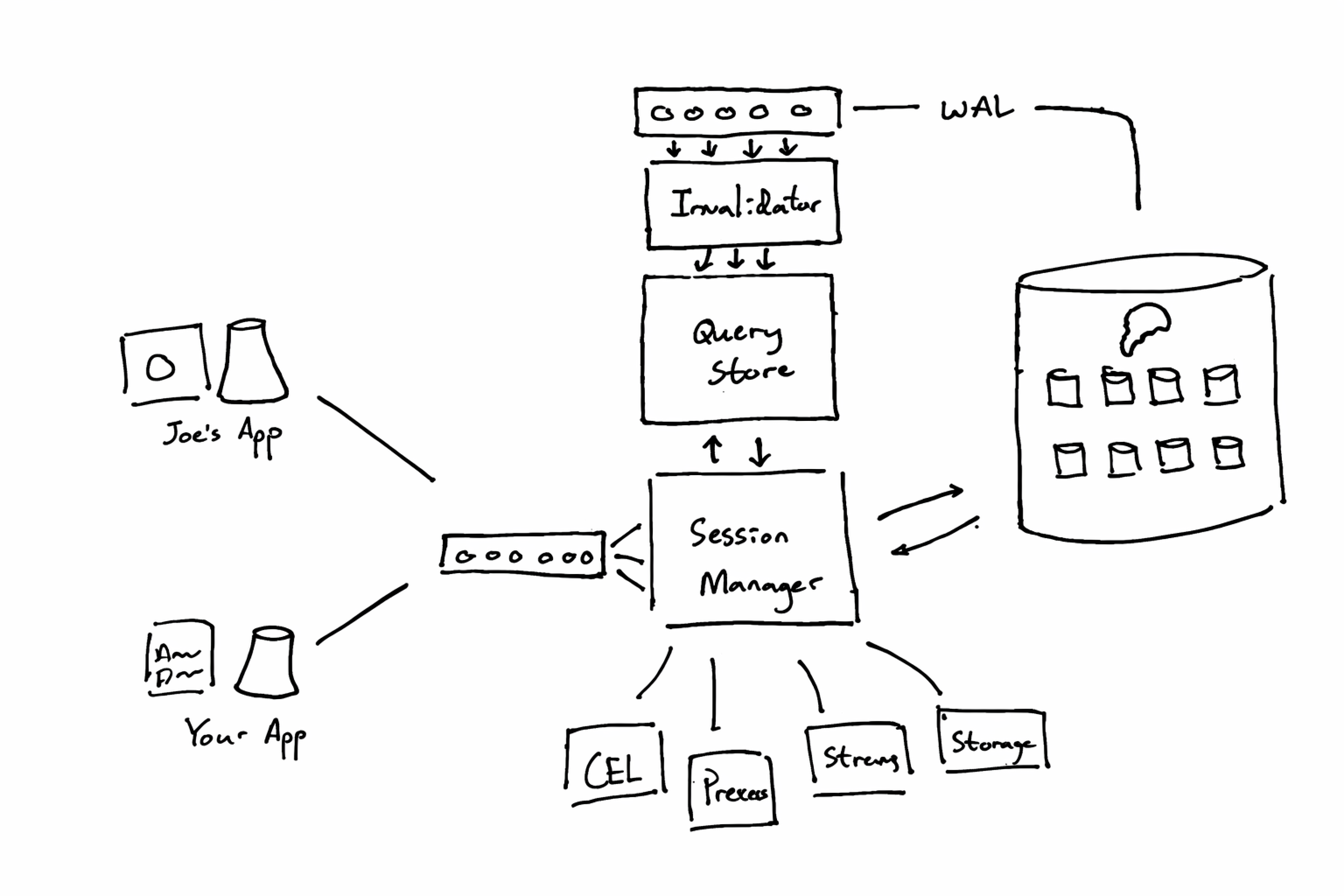 Instant 基于 Postgres 的多租户架构
Instant 基于 Postgres 的多租户架构
内置同步引擎。 每个应用默认获得实时同步、离线支持和乐观更新。不需要手动搭 WebSocket、配 IndexedDB 缓存。这本来是 Linear、Notion、Figma 级别的公司才有资源自建的基础设施。
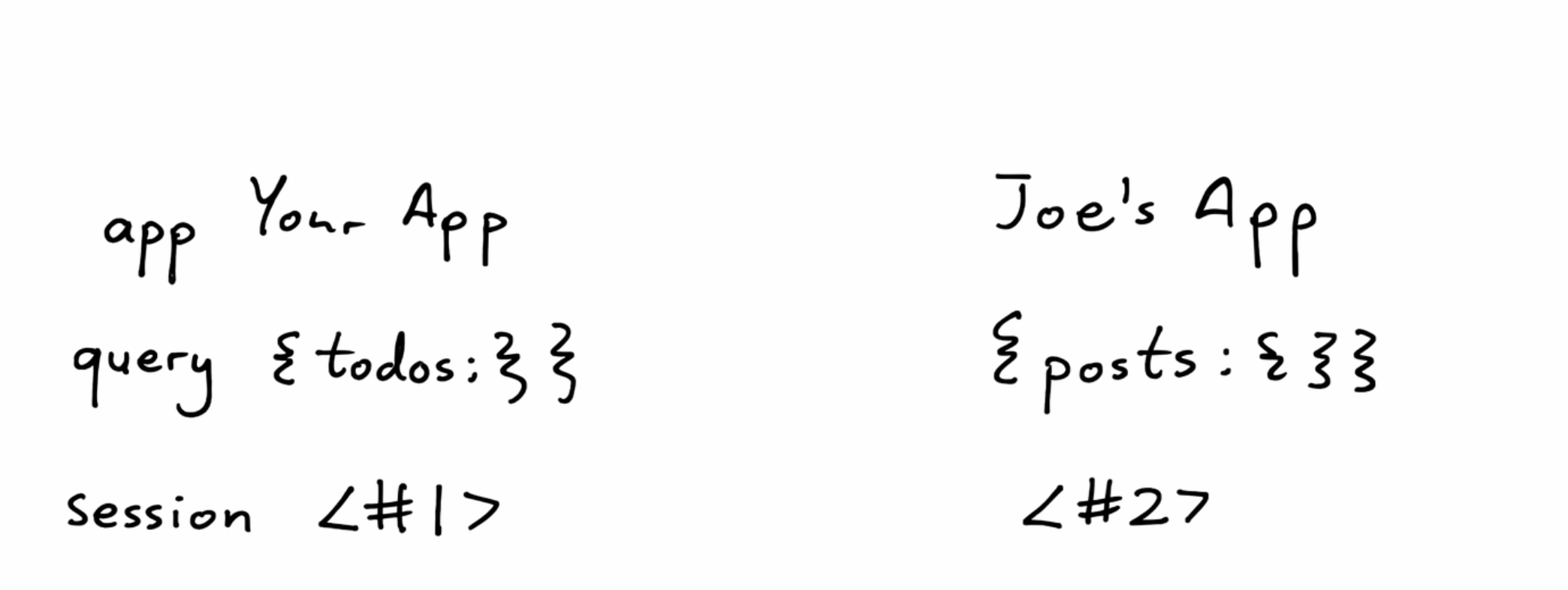 两个客户端实时同步的效果演示
两个客户端实时同步的效果演示
用 Clojure 写的后端。 这个选择比较小众,但 Clojure 在并发处理和数据变换上确实有优势。同步引擎需要处理大量并发状态,用函数式语言来写是合理的。
我的看法
Instant 切中了一个真实痛点。当 AI 编码工具让前端开发的边际成本趋近于零时,后端基础设施就成了新的瓶颈。谁能把后端做到「创建即可用」的程度,谁就能吃下 vibe coding 这波红利。
不过也有几个值得观察的点:
- 多租户的隔离性。 共享 Postgres 实例的安全隔离做到什么程度?对于生产级应用,这是绕不过去的问题。
- 查询灵活性。 文章中展示的查询 API 看起来是自定义的 DSL,而非标准 SQL。当应用复杂度上升时,这个抽象够不够用?
- 锁定效应。 一旦选择了 Instant 的数据模型和同步协议,迁移成本会不会成为问题?
从更大的图景看,InstantDB 代表的趋势值得关注:后端正在从”搭建”变成”选择”。就像 Vercel 让前端部署变成一键操作,Instant 想让后端变成一个 API 调用。在 AI 编码加速的今天,这个方向是对的。
Instant 已经完全开源,感兴趣可以去 GitHub 看看源码。对于正在用 AI 工具大量生成应用原型的开发者来说,值得试试。
如果你想在不同 AI 模型之间快速对比编码能力(比如让 Claude 写前端、GPT 写后端逻辑),试试 ofox.ai — 一个账号接入所有主流模型。