一下午提升 15 个 LLM 的编程能力:不换模型,只换 Harness
Hacker News 今天 700+ 分的热帖:I Improved 15 LLMs at Coding in One Afternoon. Only the Harness Changed。
一个独立开发者,没训练任何模型,没花一分钱 GPU 算力,只改了一个编辑工具的实现方式,就让 15 个 LLM 的编程成功率全面提升。最夸张的 case:Grok Code Fast 1 从 6.7% 飙到 68.3%,十倍改善。
这篇文章戳到了 AI Coding 领域一个被长期忽视的痛点:模型不是唯一的瓶颈,Harness 才是。
什么是 Harness?
在 AI Coding Agent 的语境下,Harness 是指模型和你的工作空间之间的一切——工具定义、输入输出格式、错误处理、状态管理。简单说,就是模型表达修改意图的那层接口。
你用 Claude Code 写代码时,Claude 不是直接往文件里写字节。它通过一个”编辑工具”告诉 Harness:”把第 15 行的 foo 换成 bar“,然后 Harness 负责执行这个操作。
这个看起来无聊到死的中间层,竟然是当前 AI 编程最大的性能瓶颈之一。
现在的编辑工具有多烂
作者 can1357 梳理了当前主流方案,每个都有致命伤:
OpenAI Codex 的 apply_patch
Codex 用一种自创的 diff 格式。模型需要输出一段符合严格规则的补丁字符串。OpenAI 大概率在推理层对自家模型做了偏置(bias token selection),让它更容易生成合规的 patch。
但换成别家模型呢?灾难。Grok 4 的 patch 失败率 50.7%,GLM-4.7 高达 46.2%。这些不是烂模型——它们只是不会说 OpenAI 的方言。
Claude Code 的 str_replace
Anthropic 的方案更直觉:给出一段”旧文本”,替换为”新文本”。简单粗暴。
但模型必须一字不差地复现原文——包括空格、缩进、换行。多个匹配?拒绝执行。经典报错 “String to replace not found in file” 在 GitHub issues 上已经有 专门的 mega thread,外加 27 个相关 issue。
Cursor 的”再来一个模型”
Cursor 的解决方案最暴力:训练一个专门的 70B 模型,专职负责把草稿编辑合并到文件里。Harness 问题难到什么程度?AI 编程领域融资最多的公司之一,决定用另一个大模型来解决它。
而且他们自己的博客里还承认:”对于 400 行以下的文件,直接全文重写的效果比 diff 更好。”
学术界的结论
JetBrains 的 Diff-XYZ benchmark 和 EDIT-Bench 的结论一致:没有任何一种编辑格式在所有模型和场景下占优。 Aider 的测试更直接——仅仅换编辑格式,GPT-4 Turbo 的成功率就从 26% 跳到 59%。
所有这些方案有一个共同缺陷:它们要求模型精确复现已经看过的内容。 模型知道该改哪里,但表达不出来——因为它必须一字不差地”引用”原文才能定位到要改的位置。
Hashline:一个简单到离谱的解法
作者的方案叫 Hashline,核心思路只有一句话:给每行代码加一个内容哈希标签。
当模型读取文件时,每行会附带一个 2-3 字符的哈希:
1
2
3
11:a3|function hello() {
22:f1| return "world";
33:0e|}
编辑时,模型引用这些标签:”替换第 2 行 f1”、”删除从 1:a3 到 3:0e 的范围”、”在 3:0e 后面插入”。
就这样。
几个关键优势:
- 不需要复现原文。 模型不用一字不差地引用旧代码,只要记住一个 2-3 字符的哈希就够了。
- 自带验证。 如果文件在模型上次读取后被改了,哈希不匹配,编辑自动拒绝。不会出现”在错误的位置做了正确的修改”这种隐蔽 bug。
- 如果模型能记住哈希,说明它确实知道自己在改什么。 这是一个天然的”理解证明”——能引用锚点,大概率真的看了那行代码。
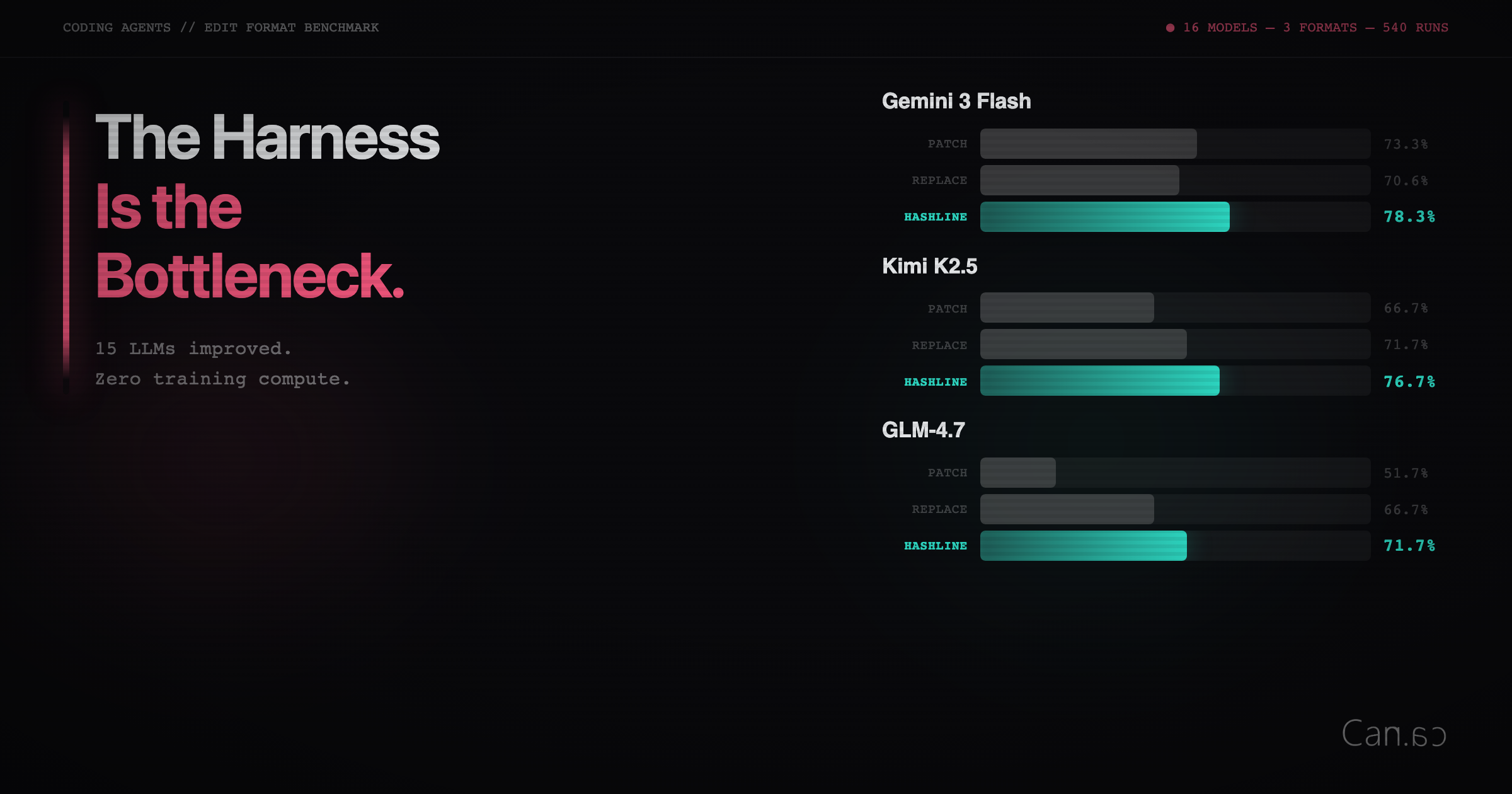
Benchmark 结果
作者在 React 代码库上设计了基准测试:随机选文件,注入 bug(运算符替换、布尔翻转、off-by-one 错误等),让模型修复。180 个任务,每个跑 3 次,16 个模型 × 3 种编辑工具。
结果一目了然:
- Patch(OpenAI 格式): 几乎对所有非 OpenAI 模型表现最差
- Replace(Anthropic 格式): 中规中矩,但天花板明显
- Hashline: 对大多数模型匹配或超越 Replace,对弱模型提升惊人
几个亮眼数据:
| 模型 | Patch | Replace | Hashline |
|---|---|---|---|
| Grok Code Fast 1 | 6.7% | — | 68.3% |
| Gemini 3 Flash | — | 73.3% | 78.3% |
| Grok 4 Fast | — | — | output tokens 减少 61% |
Grok Code Fast 1 的十倍提升说明了什么?这个模型本身的编程能力并不差,但 patch 格式的机械性失败完全遮盖了它的真实水平。 你以为模型不会写代码,其实是模型说不出来。
Grok 4 Fast 的 token 数减少 61% 更值得关注——因为模型不再陷入”编辑失败→重试→再失败→再重试”的死循环,整体效率大幅提升。
这件事为什么重要
1. 你在评价的不是模型,是 Harness
现在整个行业沉迷于 “GPT-5.3 vs Opus vs Gemini” 的对比。但当编辑格式本身能造成 60% 的成功率波动时,你确定在测的是模型能力?
就像作者说的:你在怪飞行员,但起落架是坏的。
2. 最高杠杆的优化,零训练成本
Gemini 3 Flash 提升 5 个百分点(73.3% → 78.3%),这比大多数模型升级带来的改善都大。代价?$300 的 benchmark 费用和一下午时间。没有 GPU 集群,没有 RLHF,没有数据标注。
这说明在 AI Coding 的技术栈里,工程优化的 ROI 远高于模型升级。 但行业的注意力和资金都在模型侧。
3. 开源 Harness 的价值被严重低估
作者提到了一个尖锐的现实:Anthropic 封杀了 OpenCode(一个开源 Coding Agent)访问 Claude 的途径,Google 因为他跑 benchmark 直接禁了他的 Gemini 账号。
这些大厂的逻辑是:不要自己做 Harness,用我们的。
但问题在于——没有任何一家厂商会为竞品模型优化 Harness。Anthropic 不会为 Grok 调优,xAI 不会为 Gemini 调优,OpenAI 不会为 Claude 调优。只有开源社区会为所有模型做优化,因为贡献者们本来就在用不同的模型。
作者的类比很精准:模型是护城河,Harness 是桥。烧桥只意味着更少人愿意过河。
同一天的有趣巧合
就在这篇文章发布的同一天,OpenAI 发布了 GPT-5.3-Codex-Spark,专门强调了”端到端延迟优化”——重写了推理栈、引入 WebSocket 持久连接、每轮 client/server 开销降低 80%。他们自己也在文章里承认:”随着模型变得更强,交互速度成了明显的瓶颈。”
Google 今天发布的 Gemini 3 Deep Think 在 Humanity’s Last Exam 上拿了 48.4%,ARC-AGI-2 拿了 84.6%,Codeforces Elo 3455。模型能力确实在飙升。
但模型能力飙升,编辑工具还在用 str_replace,这就像给法拉利配了个自行车轮——动力再猛,轮子打滑你也跑不起来。
写在最后
这篇文章让我想到一个更深的命题:AI 工具的”最后一英里”问题。
模型的推理能力可能已经 90 分了,但到达你代码库的时候只剩 60 分。那 30 分的损耗发生在哪里?在 prompt 格式里,在编辑工具里,在错误处理里,在重试逻辑里——全是 Harness 层的事。
这有点像早期互联网——TCP/IP 协议搞定了,但网页加载还是慢得要命,因为浏览器渲染引擎、DNS 解析、CDN 分发这些”无聊的工程”没做好。后来提速的不是换协议,是优化这些中间层。
AI Coding 工具正处于同样的阶段。模型军备竞赛吸引了所有眼球,但真正能让日常编程体验质变的,可能是 Harness 层这些看似无聊的工程优化。
一个 2-3 字符的哈希标签,就能让模型的编程成功率翻十倍。这个事实本身就够说明问题了。
“The gap between ‘cool demo’ and ‘reliable tool’ isn’t model magic. It’s careful, rather boring, empirical engineering at the tool boundary.”
从酷炫 Demo 到靠谱工具的距离,不靠模型魔法,靠的是工具边界上那些仔细的、甚至无聊的、实证驱动的工程。
原文:I Improved 15 LLMs at Coding in One Afternoon. Only the Harness Changed 项目:oh-my-pi