antirez 的 voxtral.c:用纯 C 实现语音转文字,零依赖的 AI 推理
Redis 的创造者 antirez(Salvatore Sanfilippo)又搞了个大活:用纯 C 实现了 Mistral Voxtral Realtime 4B 模型的完整推理管线。没有 Python,没有 CUDA,没有 vLLM,甚至除了 C 标准库之外零外部依赖。
这个项目叫 voxtral.c,今天登上了 Hacker News 首页。
为什么这件事值得关注
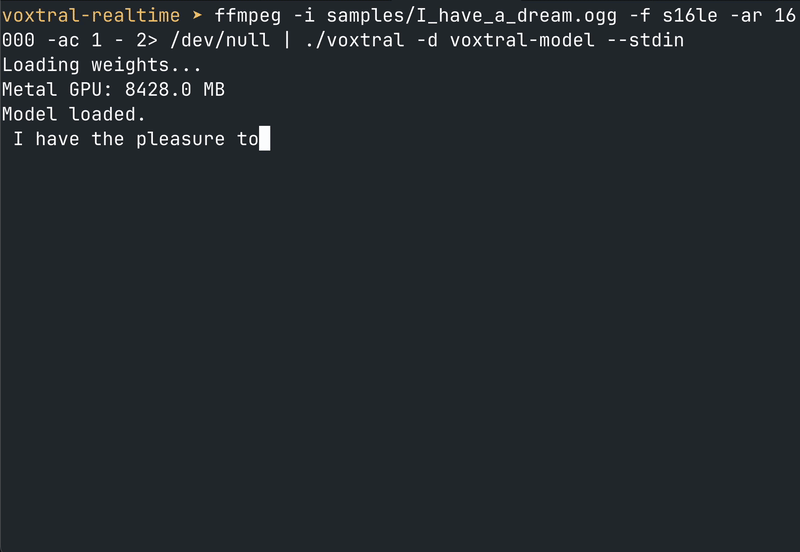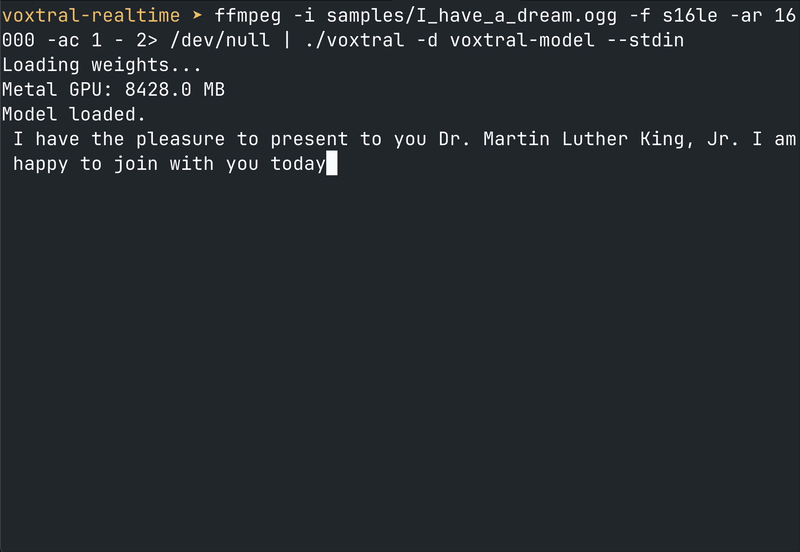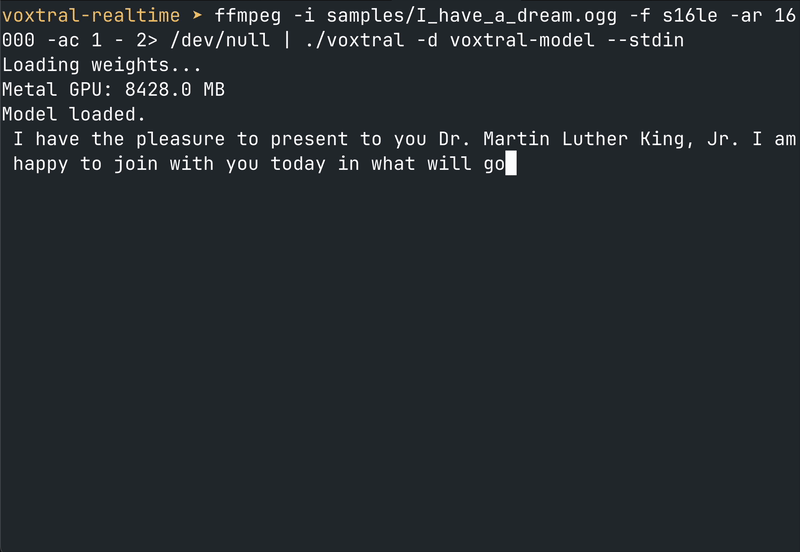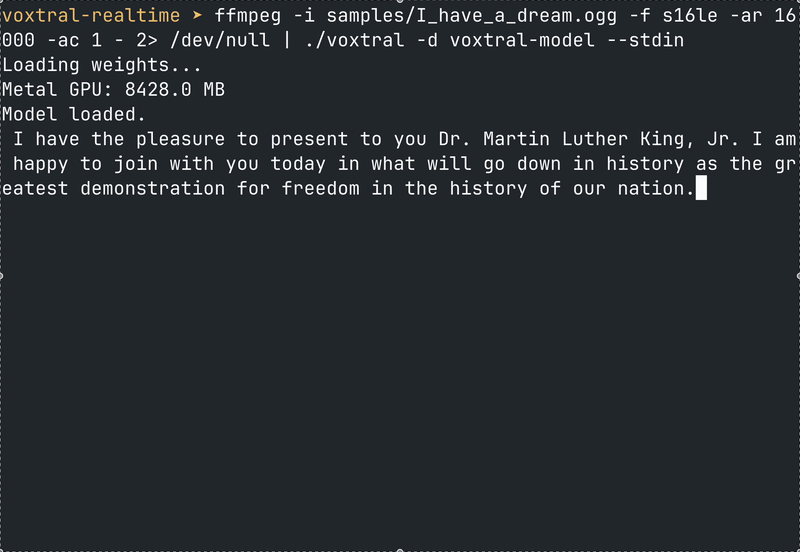 来源:素材原文 当整个行业都在围绕 Python 生态和 GPU 云服务构建 AI 基础设施时,antirez 用一个 C 项目提出了一个不同的问题:我们真的需要这么重的依赖链吗?
来源:素材原文 当整个行业都在围绕 Python 生态和 GPU 云服务构建 AI 基础设施时,antirez 用一个 C 项目提出了一个不同的问题:我们真的需要这么重的依赖链吗?
Voxtral Realtime 4B 是 Mistral 发布的开源语音转文字模型,效果不错。但官方推理方案绑定了 vLLM —— 一个庞大的 Python 推理框架。antirez 的做法是:读懂模型结构,从头用 C 实现推理逻辑,然后跑在 Apple Silicon 的 Metal GPU 上。
结果?一个 make mps && ./voxtral -d voxtral-model --from-mic 就能实时转录麦克风输入。
技术亮点
零依赖哲学
整个项目只依赖 C 标准库(MPS 后端)。权重文件通过 mmap 直接映射,加载几乎瞬间完成。没有 PyTorch,没有 ONNX,没有任何运行时开销。
这不仅仅是”炫技”。零依赖意味着:
- 部署极简 —— 编译一次,到处运行
- 启动极快 —— 不用加载 Python 解释器和一堆库
- 资源可控 —— 内存使用量一目了然,没有隐藏的 GC 或内存池
流式推理设计
voxtral.c 支持三种输入方式:WAV 文件、stdin 管道(可以接 ffmpeg)、以及实时麦克风输入。音频处理采用分块编码器(chunked encoder),内存使用量固定,不会因为音频长度增加而膨胀。
解码器的 KV cache 实现了滚动压缩(rolling compaction),超过 8192 位置后自动回收,这意味着理论上可以处理无限长度的音频流。
可读的参考实现
除了 C 版本,antirez 还提供了一个简洁的 Python 参考实现(python_simple_implementation.py),只依赖 PyTorch 和几个标准库。这个设计选择很聪明 —— C 版本追求性能,Python 版本追求可读性,两者互相印证。
antirez 的批评:开放权重 ≠ 真正开放
在 README 的 Motivation 部分,antirez 直接批评了 Mistral 的做法:
把推理限制在与 vLLM 的合作关系中,不提供自包含的参考实现,实际上限制了模型的真正影响力。
这话说得很直。很多”开源”模型发布后,你需要安装一整套特定的推理框架才能用。模型权重确实开放了,但如果运行它需要一个特定的、复杂的软件栈,那这个”开放”就打了折扣。
antirez 的 voxtral.c 本质上是一个声明:真正的开放意味着任何人都能理解并运行你的模型,不需要依赖你的生态系统。
更大的趋势:AI 推理的”回归本质”
voxtral.c 不是孤例。我们正在看到一个趋势:
从 “能跑就行” 到 “理解它如何跑”。
过去两年,大部分开发者用 AI 的方式是:调 API、装框架、跑 notebook。但越来越多的工程师开始问:底层到底发生了什么?
antirez 在 HN 上以前写过一篇关于 LLM 推理的博客,从零实现了 llama2 的推理。现在他又对语音模型做了同样的事。这种”从头理解”的精神,正是工程师文化中最珍贵的部分。
同时登上 HN 首页的还有一个 Rust 版本:voxtral-mini-realtime-rs,可以在浏览器中运行。C 和 Rust 两个版本同时出现,说明社区对”轻量级、可理解的 AI 推理”有真实需求。
实用价值
如果你有以下场景,voxtral.c 值得一试:
- 离线语音转录 —— 不依赖云服务,数据不出本机
- 嵌入式/边缘设备 —— 零依赖意味着容易移植
- 学习模型推理 —— 一个 C 文件比 vLLM 的代码库更容易读懂
- macOS 日常使用 —— Apple Silicon 上实时麦克风转录,可以当会议记录工具用
当然,antirez 自己也说了:这个项目还需要更多测试。特别是长时间转录场景下 KV cache 的稳定性,目前还没有充分验证。
我的看法
AI 行业正在经历两个平行的趋势。一边是越来越大的模型、越来越重的基础设施、越来越高的算力门槛。另一边是像 antirez 这样的工程师,用最朴素的工具证明:4B 参数的模型,一台笔记本,一个 C 编译器,就够了。
这两个趋势不矛盾。大模型需要大基础设施来训练,但推理端完全可以做到轻量化。voxtral.c 证明的不是 C 比 Python 更好,而是 理解你在用的工具比盲目依赖框架更重要。
作为一个十年工程师,我对这种项目有天然的好感。不是因为它多酷,而是因为它代表了一种态度:不接受”它就是这样工作的”,要搞清楚为什么。
这种态度,在 AI 时代尤其稀缺,也尤其珍贵。
项目地址:github.com/antirez/voxtral.c
HN 讨论:Pure C, CPU-only inference with Mistral Voxtral Realtime 4B speech to text model